NER案例
例子:命名实体识别(NER)
假设我们有如下句子:
"John lives in New York."
目标是识别出句子中的命名实体,并将其标注为对应的标签。对于这个例子,我们使用 B-LOC 表示位置实体的开始,I-LOC 表示位置实体的内部,B-PER 表示人名实体的开始,O 表示其他。
步骤
- 输入序列:
"John lives in New York."
- 真实标签序列:
B-PER O O B-LOC I-LOC
LSTM+CRF 模型
-
LSTM 层:
- 首先,将输入句子转化为词向量。
- 这些词向量输入到 LSTM 层,生成每个时间步的特征表示。
假设词向量维度为 100,LSTM 层输出的每个时间步的特征表示维度为 200(双向 LSTM)。
LSTM 层输出:
[h_1, h_2, h_3, h_4, h_5]
其中,(h_i) 是第 (i) 个词的特征表示。
-
CRF 层:
- LSTM 输出的特征表示输入到 CRF 层。
- CRF 层计算每个可能标签序列的分数。
假设对于每个词,CRF 层输出的标签得分矩阵为:
h_1: [3, 2, 1, 0] (对应标签:B-PER, B-LOC, I-LOC, O)
h_2: [1, 3, 2, 4]
h_3: [2, 1, 4, 3]
h_4: [2, 3, 0, 1]
h_5: [1, 3, 4, 2]
- 计算对数似然:
- 模型为真实标签序列 (Y = [B-PER, O, O, B-LOC, I-LOC]) 计算分数:
s(X, Y) = 3 + 4 + 3 + 3 + 4 = 17
-
计算所有可能标签序列的分数总和:
假设所有可能标签序列的分数总和为 1000。
-
对数似然:
\text{log-likelihood}(X, Y) = 17 - \log 1000
训练目标
在训练过程中,我们通过最大化上述对数似然来调整模型参数,使得真实标签序列的得分尽可能高,相对其他所有可能标签序列的分数总和尽可能大。
总结
通过这个例子,我们看到 LSTM+CRF 模型如何处理输入序列并计算输出标签的分数。通过最大化对数似然,我们希望模型能够更准确地预测输入序列的真实标签。在实际训练中,这个过程会通过多次迭代和参数优化来实现。
主流技术方案
小型神经网络模型
1. RNN/LSTM + CRF
步骤:
-
数据预处理:
- 标注数据集(如 CoNLL-2003)。
- 将文本转换为词向量(可以使用预训练的词向量,如 Word2Vec 或 GloVe)。
-
模型构建:
- 构建 RNN/LSTM 层,用于捕捉句子中的上下文信息。
- 在 RNN/LSTM 层之后添加一个全连接层,将输出映射到标注空间。
- 使用 CRF 层进行标注解码,以考虑标注之间的依赖关系。
-
模型训练:
- 使用训练集训练模型,优化目标是最大化条件随机场的对数似然。
-
模型评估:
- 使用测试集评估模型的性能,计算准确率、召回率和 F1 分数。
代码示例(基于 PyTorch):
import torch
import torch.nn as nn
from torchcrf import CRF
class LSTM_CRF(nn.Module):
def __init__(self, vocab_size, tagset_size, embedding_dim, hidden_dim):
super(LSTM_CRF, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, hidden_dim // 2, num_layers=1, bidirectional=True)
self.hidden2tag = nn.Linear(hidden_dim, tagset_size)
self.crf = CRF(tagset_size)
def forward(self, sentence):
embeds = self.embedding(sentence)
lstm_out, _ = self.lstm(embeds)
tag_space = self.hidden2tag(lstm_out)
return tag_space
def loss(self, sentence, tags):
emissions = self.forward(sentence)
loss = -self.crf(emissions, tags)
return loss
def decode(self, sentence):
emissions = self.forward(sentence)
return self.crf.decode(emissions)
# 初始化模型、损失函数和优化器
model = LSTM_CRF(vocab_size, tagset_size, embedding_dim, hidden_dim)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
预训练模型
BERT(Bidirectional Encoder Representations from Transformers)属于预训练模型。BERT 是由 Google 提出的,它采用了 Transformer 架构,通过在大规模语料库上进行无监督的预训练,然后在特定任务上进行微调,从而在多种自然语言处理任务中取得了卓越的表现。
BERT 的预训练过程包括两个主要步骤:
-
掩码语言模型(Masked Language Model, MLM):在预训练过程中,BERT 会随机遮掩输入文本中的一些词,然后训练模型根据上下文来预测这些被遮掩的词。这使得 BERT 能够捕捉到双向的上下文信息。
-
下一句预测(Next Sentence Prediction, NSP):在预训练过程中,BERT 还通过给定两句话并预测第二句话是否是紧跟第一句话的连续句子,来学习句子级别的关系。
经过上述预训练后,BERT 可以在各种下游任务(如文本分类、问答系统、命名实体识别等)中通过微调(即在小规模标注数据上进行有监督训练)来适应特定任务的需求。这种预训练-微调的方式使得 BERT 在很多自然语言处理任务中都表现出色。
1. BERT + CRF
步骤:
-
数据预处理:
- 同样,使用标注数据集。
- 将文本转换为 BERT 输入格式(使用 BERT 的 tokenizer)。
-
模型构建:
- 使用预训练的 BERT 模型,将其输出作为特征向量。
- 在 BERT 输出之后添加一个 CRF 层,用于标注解码。
-
模型训练:
- 使用训练集训练模型,优化目标是最大化条件随机场的对数似然。
-
模型评估:
- 使用测试集评估模型性能。
代码示例(基于 Hugging Face Transformers):
from transformers import BertTokenizer, BertModel
from torchcrf import CRF
class BERT_CRF(nn.Module):
def __init__(self, bert_model_name, tagset_size):
super(BERT_CRF, self).__init__()
self.bert = BertModel.from_pretrained(bert_model_name)
self.hidden2tag = nn.Linear(self.bert.config.hidden_size, tagset_size)
self.crf = CRF(tagset_size)
def forward(self, input_ids, attention_mask):
outputs = self.bert(input_ids, attention_mask=attention_mask)
sequence_output = outputs[0]
tag_space = self.hidden2tag(sequence_output)
return tag_space
def loss(self, input_ids, attention_mask, tags):
emissions = self.forward(input_ids, attention_mask)
loss = -self.crf(emissions, tags, mask=attention_mask)
return loss
def decode(self, input_ids, attention_mask):
emissions = self.forward(input_ids, attention_mask)
return self.crf.decode(emissions, mask=attention_mask)
# 初始化模型、损失函数和优化器
model = BERT_CRF('bert-base-uncased', tagset_size)
optimizer = torch.optim.Adam(model.parameters(), lr=3e-5)
# 使用BERT的tokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
参考文献
这些步骤和代码示例提供了一个基本框架,具体实现时需要根据数据集和实际需求进行调整和优化。
UIE(通用信息抽取)方案
信息提取(IE)旨在从非结构化文本中识别和构造用户指定的信息(Andersen et al.,1992;Grishman,2019)。IE任务因其不同的任务(实体(entity)、关系(relation)、事件(event)、情感(sentiment)等)、异构结构(片段(span)、三元组(triplets)、记录(records)等)和特定于需求的模式而高度多样化(Grishman和Sundheim,1996;Mitchell等人,2005;Ji和Grishman,2011)。
Unified Structure Generation for Universal Information Extraction 23 Mar 2022
提出概念
目前,大多数IE方法都是面向特定任务的,这导致了针对不同IE任务的专用体系结构、独立模型和专用知识源。这些任务专用解决方案极大地阻碍了IE系统的快速体系结构开发、有效的知识共享和快速跨领域适应。首先,为大量IE任务/设置/场景开发专用架构非常复杂。其次,学习孤立模型严重限制了相关任务和环境之间的知识共享。最后,构建专门用于不同IE任务的数据集和知识源既昂贵又耗时。因此,开发一个通用IE体系结构将非常有益,该体系结构可以统一建模不同的IE任务,自适应预测异构结构,并有效地学习各种资源,论文称之为Universal IE。
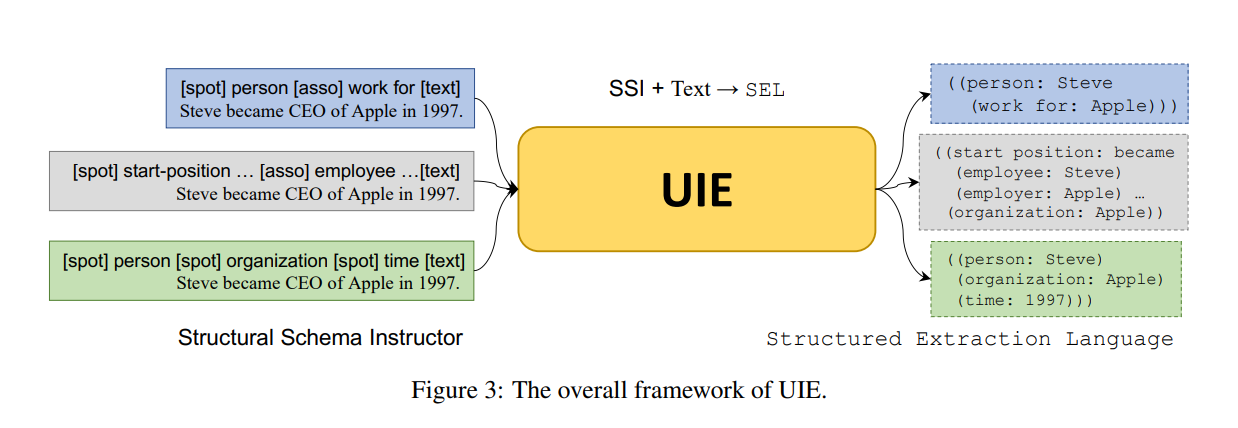
这张图片展示了一个名为UIE(Unified Information Extraction)的框架,其整体结构如图所示。UIE通过使用结构化模式指导(Structural Schema Instructor,简称SSI)和结构化抽取语言(Structured Extraction Language,简称SEL)来进行信息抽取。
-
Structural Schema Instructor (SSI):
- SSI用于定义不同的结构化模式,用以从文本中抽取信息。
- 图中展示了三种不同的结构化模式:
- 第一种模式:[spot] person [asso] work for [text],例如“Steve became CEO of Apple in 1997.”,这里的[spot]、[asso]、[text]分别代表要抽取的人、关系和文本信息。
- 第二种模式:[spot] start-position … [asso] employee …[text],同样的文本句子,被识别为“Steve became CEO of Apple in 1997.”,以不同的方式组织。
- 第三种模式:[spot] person [spot] organization [spot] time [text],同样的句子,被识别为“Steve became CEO of Apple in 1997.”,组织更为详细。
-
Unified Information Extraction (UIE):
- UIE接受SSI和文本作为输入,生成结构化的抽取语言(SEL)。
- 不同的SSI模式指导UIE从文本中提取相应的信息,并生成对应的SEL。
-
Structured Extraction Language (SEL):
- 图右侧展示了不同的SEL格式:
- 第一种模式生成的SEL:((person: Steve) (work for: Apple))
- 第二种模式生成的SEL:((start position: became) (employee: Steve) (employer: Apple) …)
- 第三种模式生成的SEL:((person: Steve) (organization: Apple) (time: 1997))
- 图右侧展示了不同的SEL格式:
InstructUIE: Multi-task Instruction Tuning for Unified Information Extraction 17 Apr 2023
该论文提出了一个名为InstructUIE的任务元信息框架,用于指导预训练语言模型在命名实体识别、关系提取和事件抽取等信息抽取任务中的表现。该框架包括两个主要部分:任务规范和辅助任务。其中,任务规范将每个任务实例格式化为四个属性:任务指令、选项、文本和输出。
- 任务指令提供了详细的指南,说明如何从输入文本中提取相关信息并产生所需的输出结构。
- 选项是给定输入的可能输出标签约束,它们提供了映射预测输出到相应语义概念的信息。
- 文本是任务实例的输入句子,它与任务指令和选项一起馈入预训练语言模型,以生成所需的任务输出序列。
- 输出是从原始标记转换而来的样本句子。
- 对于命名实体识别任务,输出格式为“实体标签:实体范围”。
- 对于关系提取任务,输出格式为“关系类型:头实体,尾实体”。
- 对于事件抽取任务,输出格式为“事件标签:触发词,参数标签:参数范围”。
取得成果
- 取得了和BERT监督学习可比较的一个效果。
- 在zero-shot的能力上取得了sota,比gpt3.5sota也好得多。
- 利用一个multi-task模型可以解决大量的任务
UIE开源模型
PaddlePaddle/uie-base
PaddlePaddle/uie-base 模型旨在解决各种信息抽取(IE)任务。它采用统一的文本到结构生成框架,能够处理不同的抽取结构,并通过基于架构的提示机制自适应地生成目标抽取。该模型基于 ERNIE 3.0 预训练语言模型,并在大量信息抽取数据上进行了微调。它支持广泛的任务,包括实体、关系、事件和情感抽取,并在多个数据集和设置(包括有监督、低资源和少样本场景)中实现了最新的性能
API文档
ZWK/InstructUIE
InstructUIE 是另一种信息抽取模型,专注于基于指令的信息抽取。它使用自然语言指令来引导抽取过程,使其能够在不需要任务特定微调的情况下处理各种任务。该模型旨在通过理解和遵循类人指令来处理复杂的抽取场景,从而显著提高其在现实应用中的适应性和有效性。
「真诚赞赏,手留余香」
 YuTian Blog
YuTian Blog
真诚赞赏,手留余香
使用微信扫描二维码完成支付
